Abstract
In this article, two parameter estimation using penalized likelihood method in the linear mixed model is proposed. In addition, by considering the stochastic linear restriction for the vector of fixed effects parameters we are introduced the stochastic restricted two parameter estimation. Methods are proposed for estimating variance parameters when unknown. Also, the superiority conditions of the two parameter estimator over the best linear unbiased estimator, and the stochastic restricted two parameter estimator over the stochastic restricted best linear unbiased estimator are obtained under the mean square error matrix sense. Methods are proposed for estimating of the biasing parameters. Finally, a simulation study and a numerical example are given to evaluate the proposed estimators.
Keywords: Linear mixed model, two parameter estimation, stochastic restricted two parameter estimation, matrix mean square error
1. Introduction
Today many datasets lack the assumption of data independence, which is the main presupposition of many statistical models. For example data collected by cluster or hierarchical sampling, lengthwise studies and frequent measurements or in medical research that simultaneously provides data from one or more body members, the assumption of data independence is unacceptable because the data of a cluster, a group, or an individual are interdependent over time [1]. The default requirement for fitting linear models is the assumption of data independence that does not exist so the use of these models although it leads to unbiased estimates but the variance of estimating coefficients is strongly influenced by the default of data independence. In other words if the data are not independent then the standard error and therefore the confidence interval and the result test result will be for non-trust regression coefficients. Therefore in analyzing these data it is necessary to use methods that can consider this dependence. One of the most important ways to solve this problem is linear mixed models which are generalizations of simple linear models that provide the possibility of random and fixed effects with each other. Linear mixed models are used in many fields of physical, biological, medical and social sciences [2-5].
We consider the linear mixed model (LMM) as follows:
where is an vector of observations, with is an design matrix corresponding to the -th random effects factor and , is an observed design matrix for the fixed effects, is a parameter vector of unknown fixed effects, is a unobservable vector of random effects and is an unobservable vector of random errors. and are independent and have a multivariate normal distribution as
where and are and vectors of variance parameters corresponding to and , respectively. Henderson et al. [6-7] introduced the set of equations called mixed model equations, and obtained and as
where and . They and are called the best linear unbiased estimator (BLUE) and the best linear unbiased predictor (BLUP), respectively. One of the most common estimators in linear regression is the ordinary least squares (OLS) estimator, which in the case of multicollinearity may lead to estimates with adverse effects such as high variance [8]. To reduce the effects of multicollinearity. Liu et al. [9-10] proposed the ridge estimator and the Liu estimator respectively, which are the well-known alternatives of the OLS estimator. Yang and Chang [11] obtained the two parameter estimator “Using the mixed estimation technique introduced by Theil et al. [12-13]. They considered the prior information about in the form of restriction as where and are respectively the ridge, Liu parameters and the ridge estimator”.
In , authors such as Gilmour et al. [14], Jiming and Lahiri [15] and Patel and Patel [16], considered a state where the matrix is singular. Liu and Hu [10] and Eliot et al. [17] inquired the ridge prediction in LMM. Liu and Hu [10] are obtained and as
where and are the ridge estimator of and the ridge predictor of respectively. Özkale and Can [18] gave “an example from kidney failure data” to evaluate ridge estimator in linear mixed model. Kuran and Özkale [19] obtained the mixed and stochastic restricted ridge predictors by using Gilmour approach. They introduced “stochastic linear restriction as where is an vector, is an known matrix of rank and is an random vector that is assumed to be distributed with and where is vector of variance parameters corresponding to Also and are independent”
Then derived the stochastic restricted estimator of and the stochastic restricted predictor of respectively, as
Furthermore, they obtained the stochastic restricted ridge estimator of and the stochastic restricted ridge predictor of respectively, as
In this article, we obtain the new two parameter estimations in linear mixed models by taking Yang and Chang’s ideas [11] and considering restriction In Section we follow the idea of Henderson’s mixed model equations to get the two parameter estimator. Then, by setting stochastic linear restrictions on the vector of fixed effects parameters, we derive the stochastic restricted two parameter estimation. In Section 3, estimates for the variance parameters are obtained when unknown. In Section 4, under the mean square error matrix (MSEM) sense we offer comparisons of new two parameter estimators. In Section 5, Methods are proposed for estimating of the biasing parameters. In Sections 6 and 7, a simulation study and a real data analysis is given. Finally, summary and some conclusions are given in Section 8.
2. The proposed estimators
Under model (1), we have
and the joint distribution of and is given by
where and are nonsingular. If the restriction used by Yang and Ghang [11] in linear regression is transferred to linear mixed model, we can produce the two parameter estimator using “penalized term” idea. So by unifying restriction with model (1) to give
where
with
Then and are jointly distributed as
where .The conditional distribution of given is and the logarithm joint density of and given by
The penalized log-likelihood function is obtained by succession and as follows:
From Eq. (3), we get the partial derivative with respect to and then set the equations to zero and by using and to denote the solutions give
By solving the Eq. (5), is
Using into Eq. (4) we get
Also using this equation equals to
In Eq. (8), if we put is obtained as follows
Due to we get
Using Eq. (10), equals to .
In section, we obtain the stochastic restricted two parameter estimation. For this, the stochastic Linear restrictions can be unified to model (1) and the restriction to give
where
Then, the conditional distribution of given is and the logarithm joint density of and given by
Substituting and to , the penalized log-likelihood function is obtained as follows:
From Eq. (12), we get the partial derivative with respect to and then set the equations to zero and by using and to denote the solutions give
By solving these equations similar to Eqs. (4) and (5), the following results are obtained
3. Estimation of variance parameters
In linear mixed models, the variance parameter within and are often unknown that several methods have been proposed by [16,20-22]
to estimate them. In this section, we estimate the variance parameters using the ML method. The marginal distribution of is , therefore we can write the marginal log-likelihood function of
where and and are vectors of unknown parameters, respectively. Differentiating the Eq. (17) with respect to and the partial derivatives is obtained as
where . Setting Eqs. (18)-(20) equal to zero and using and and instead of and gives
Solving Eqs. (21) and (23) yields the estimators
Eq. (23) depends on and so iterative procedures must be used to solve 's. In the statistical literature, there are four iterative procedures to estimates variance parameters, which include: "Newton-Raphson (NR), Expectation Maximization algorithm (EM), Fisher Scoring (FS) and the Average Information (AI) algorithms". See [22] for details of these procedures. Note that in the stochastic restricted two parameter methods, the ML estimators is obtained similar Eqs. (21),(22) and (23).
4. Comparison of estimators
In this section, we compare the estimator with and the estimator with using the mean squares error matrix (MSEM) sense. The estimator is superior to with respect to the MSEM sense, if and only if that is, is a positive definite (pd) matrix. The mean-square error matrix for the estimator is given as
The variance matrix of is
where The bias is given as
The mean-square error matrix for the estimator is given as
where
and
4.1 Comparison the Estimator β̃(k,d) with β̃
The of is where and the of is
The estimator is superior to the estimator under the MSEM sense, if and only if then
According to Farebrother if then the necessary and sufficient condition for to be superior to is .
5. Selection of parameters k and d
In the linear regression model, choosing the parameter is important so many statisticians were suggested several methods for obtaining this parameter. These methods were proposed by many researchers [23-29] and others. According to Ozkale and Can [18], we rewrite model (1) in the form of a marginal model in which random effects are not explicitly defined:
Because is pd, then there is a nonsingular symmetric matrix such that . If we multiply both sides of model (42) by , we get , where ,
and . The matrix is symmetric, so there is an orthogonal matrix such that and where
are the ordered eigenvalues of . Then model (26) can be rewritten in a canonical form as , where and . Under this model, we get the following representation:
We use to find the optimal values of and , where is the mean square error. Let fixed, the optimal value of the can be obtained by minimizing the following statement
Notice that Therefore, getting we obtain Since the optimal depends on unknown and then according Hoerl and Kennard [9] we can get the estimate of by substituting and as follows:
where and are the unbiased estimators and . According to the estimator of which Kibria [25] and Hoerl and Kennard [9] proposed, the harmonic mean value of in (27) is
Now, let fixed, and we get the optimal value by minimizing . Therefore getting
Since is always be positive, in this section we get the positive condition of the estimator in Eq. (27). For this purpose, we use the following theorem.
Theorem 5.1
If ,
for all then are always positive.
Proof.
If , then the values of are positive. Since and must be positive for all . Then we get
and because depends on the unknown parameters and so their unbiased estimators are replaced. Therefore is always positive if is selected as .
Note that is always less than one and since must be between zero and one, we consider the inequality as follows
Since in (28) depends on and the estimators of in depend on , we consider an iterative method for these parameters by applying the following method. Step calculate from Eq. (29). Step 2, calculate by using in step 1 . Step calculate from Eq. (28) by using the estimator in Step 2 . Step if is not between zero and one use
6. A simulation study
In this section, we compare the performance of and with a simulation study. For this purpose, we calculate the estimated mean square error (EMSE) with various values of sample size, variance and degree of collinearity. Following McDonald and Galarneau [27], we are computed the fixed effects as
where independent standard normal are pseudo-random numbers and is the correlation between any two fixed effects. Three different sets of were considered as 0.75,0.85 and The matrix is produced in a completely randomized design. Observation on responses are then determined by
We consider two designs that in the first design and in the second design . Also, the same value and are taken in both designs. Following Ozcale and Can [18], the vector was chosen as the eigenvector corresponding to the largest eigenvalue of the matrix”. The variances matrix of random effects and are and , respectively. They are generated from the normal distribution . We are considered and .The trial was replicated 1000 times by generating and For each simulated data set derived and and then the estimated mean squared error (EMSE) calculated as calculated the relative mean square (RMSE) as
when is greater than one, it indicates that the estimator superior to the estimator . For the stochastic linear restriction the matrix is and generated from the normal distribution and the matrix is generated from the normal distribution where is taken as ) with . In Table 1, we obtain the values of EMSE and RMSE for and . We have the following results for Table 1:
(i) In the whole table, the EMSE values of is less than . Also, the EMSE values of is less than . In general, the EMSE values of is less than all estimators.
(ii) As and increase, the EMSE values of the estimators increase.
(iii) As increases, difference between the EMSE values of the two parameter estimators and the EMSE values of the best linear unbiased estimators increase. This implies an increase in the improvement of the two-parameter estimators.
Table 1. Estimated
and SMSE values with
and
| |
|
|
| ni
|
3
|
7
|
3
|
7
|
|
|
0.0001526
|
7.3974e-05
|
0.0003053
|
0.0001479
|
|
|
0.0001461
|
7.1668e-05
|
0.0002923
|
0.0001433
|
|
|
0.0001032
|
6.9166e-05
|
0.0001912
|
0.0001332
|
|
|
9.9335e-05
|
6.7089e-05
|
0.0001845
|
0.0001293
|
|
|
1.4795
|
1.0695
|
1.5965
|
1.1104
|
|
|
1.4716
|
1.0682
|
1.5845
|
1.1083
|
|
|
1.0389
|
1.0309
|
1.0363
|
1.0301
|
|
|
|
|
| ni
|
3
|
7
|
3
|
7
|
|
|
0.0002198
|
0.0003460
|
0.0004396
|
0.0002387
|
|
|
0.0002076
|
0.0001134
|
0.0004153
|
0.0002269
|
|
|
0.0001332
|
0.0001045
|
0.0002562
|
0.0002111
|
|
|
0.0001277
|
0.0002460
|
0.0002459
|
0.0002014
|
|
|
1.6495
|
1.1414
|
1.7156
|
1.1308
|
|
|
1.6263
|
1.1373
|
1.6889
|
1.1266
|
|
|
1.0430
|
1.1219
|
1.0418
|
1.0481
|
|
|
|
|
| ni
|
3
|
7
|
3
|
7
|
|
|
0.0005729
|
0.0003460
|
0.0011459
|
0.0006920
|
|
|
0.0005033
|
0.0003044
|
0.0010066
|
0.0006088
|
|
|
0.0002762
|
0.0002760
|
0.0005201
|
0.0005272
|
|
|
0.0002578
|
0.0002460
|
0.0004927
|
0.0004716
|
|
|
2.0743
|
1.2533
|
2.2030
|
1.3125
|
|
|
1.9524
|
1.2369
|
2.0429
|
1.2908
|
|
|
1.0713
|
1.1219
|
1.0556
|
1.1178
|
7. Real data analysis
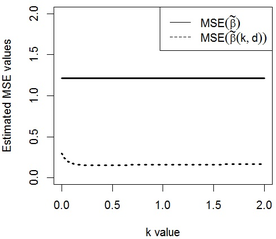
We consider a data set, which is known as the Egyptian pottery data to show the behavior of the new Restricted and Unrestricted Two-Parameter Estimators. This data set arises from an extensive archaeological survey of pottery production and distribution in the ancient Egyptian city of Al-Amarna. The data consist of measurements of chemical contents (mineral elements) made on many samples of pottery using two different techniques, NAA and ICP (see Smith et al. [30] for description of techniques). The set of pottery was collected from different locations around the city. We fit the data set by linear mixed model as where is vector of response variables, and which are regression matrix with dimensions and respectively. First, we are estimated the variance components by consider and Then, by calculating the eigenvalues of the condition number 8322860 is obtained, which indicate severe multicollinearity. We considered the stochastic linear restrictions as and selected 3 available data in the previous sections to the Egyptian pottery data. and are obtained using the iterative method introduced at the end of section 5,0.348 and 0.373 respectively. In Table 2, the estimated values of the estimators are obtained by replacing in the corresponding theoretical MSE equations. We can see the estimated MSE values of is less than . Also, the estimated MSE values of is less than . In general, the estimated MSE values of is less than all estimators. So, we conclude that the stochastic restricted two parameter estimator performs better than the other estimators. Note that in the results obtained for this data, all eigenvalues of and are positive and the condition of Theorem 4.1 and Theorem 4.2 are true. In Figure 1, a plot of the estimated MSE values of and against in the interval [0,2] with fixed is drawn. Because is not dependent on , its estimated value is the same for all values. It is obvious that estimated values of is always less than . Altogether, it is obvious that the two parameter estimators can perform better than the in MSEM criterion under conditions.
Table 2. Estimated MSE values of the proposed estimators
| |
|
|
|
|
| EMSE
|
1.216069
|
1.201379
|
0.1544953
|
0.1541745
|
|
| Figure 1. The estimated mean square error values of the estimators versus with
|
8. Conclusion
In this article, we proposed the two parameter estimator and the stochastic restricted two parameter estimator to overcome the effects of the multicollinearity problem in linear mixed models. We also obtained estimates of variance parameters and then using the mean squared error matrix sense made comparisons between the proposed estimators and some other estimators. Finally, we proposed methods for estimating biasing parameters and provided a simulation study and a data example to illustrate performance of new estimators.
Disclosure statement
No potential conflict of interest was reported by the authors..
Funding
The research was supported by the Slamic Azad University.
References
[1] Zenzile T.G. Community health workers' understanding of their role in rendering maternal, child and
women's health services. Diss. North-West University, 2018.
[2] Fiona S., Dierenfeld E.S., Langley-Evans S.C., Hamilton E., Lark R.M., Yon L., Watts M.J. Potential bio-indicators for assessment of mineral status in elephants. Sci. Rep-UK., 10(1):1-14, 2020.
[3] Rajat K., Guler I., Nerkar A. Entangled decisions: Knowledge interdependencies and terminations of patented inventions in the pharmaceutical industry. Strateg. Manage. J., 39(9):2439-2465, 2018.
[4] Adam, L., Corsi D.J., Venechuk G.E. Schools influence adolescent e-cigarette use, but when? Examining the interdependent association between school context and teen vaping over time. J. Youth. Adolescence, 48(10):1899-1911, 2019.
[5] Zhiyi C., Zhu S., Niu Q., Zuo T. Knowledge discovery and recommendation with linear mixed model. IEEE Access., 8:38304-38317, 2020.
[6] Henderson C.R. Estimation of genetic parameters. Ann. Math. Stat., 21:309–310, 1950.
[7] Henderson C.R., Searle S.R., VonKrosig C.N. Estimation of environmental and genetic trends from records subject to culling. Biometrics, 15:192–218, 1959.
[8] Farebrother R.W. Further results on the mean square error of ridge regression. J. Royal. Stat. Soc., Series B (Methodological), 38(3):248-250, 1976.
[9] Liu K. A new class of biased estimate in linear regression. Commun. Statist. Theor. Meth., 22(2):393–402, 1993.
[10] Liu X.Q., Hu P. General ridge predictors in a mixed linear model. J. Theor. Appl. Stat., 47:363–378, 2013.
[11] Yang H., Chang X. A new two-parameter estimator in linear regression. Commun. Statist. Theor. Meth., 39:923–934, 2010.
[12] Theil H., Goldberger A.S. On pure and mixed statistical estimation in economics. Int. Econ. Rev., 2:65–78, 1961.
[13] Theil H. On the use of incomplete prior information in regression analysis. J. Amer. Statist. Assoc., 58,401–414, 1963.
[14] Gilmour A.R., Cullis B.R., Welham S.J., Gogel B.J., Thompson R. An efficient computing strategy for predicting in mixed linear models. Comput. Statist. Data Anal., 44:571–586, 2004.
[15] Jiming J., Lahiri P. Mixed model prediction and small area estimation. Test., 15(1):1-96, 2006.
[16] Patel S.R., Patel N.P. Mixed effect exponential linear model. Commun. Statist. Theor. Meth., 21(9):2721-2740, 1992.
[17] Eliot M.N., Ferguson J., Reilly M.P., Foulkes A.S. Ridge regression for longitudinal biomarker data. Int. J. Biostat., 7:1–11, 2011.
[18] Özkale M.R., Can F. An evaluation of ridge estimator in linear mixed models: an example from kidney failure data. J. Appl. Statist., 44(12):2251–2269, 2017.
[19] Kuran O., Ózkale M.R. Gilmour’s approach to mixed and stochastic restricted ridge predictions in linear mixed models. Linear. Algebra. Appl., 508:22–47, 2016.
[20] Hartley H.O., Rao J.N. Maximum-likelihood estimation for the mixed analysis of variance model. Biometrika, 54:93–108, 1967.
[21] Lee Y., Nelder J.A. Generalized linear models for the analysis of quality-improvement experiments. Canad. J. Stat., 26(1):95–105, 1998.
[22] Hoerl A.E., Kennard R.W. Ridge regression: biased estimation for non-orthogonal problems. Technometrics, 12:55–67, 1970.
[23] Hoerl A.E., Kennard R.W. Ridge regression: iterative estimation of the biasing parameter. Commun. Statist. Theor. Meth., 5:77–88, 1976.
[24] Wencheko E. Estimation of the signal-to-noise in the linear regression model. Statist. Pap., 41:327–343, 2000.
[25] Kibria B.M. Performance of some new ridge regression estimators. Commun. Statist. Simul. Computat., 32:419–435, 2003.
[26] Mallows C.L. Some comments on Cp. Technometrics, 15:661–675, 1973.
[27] McDonald G.C., Galarneau D.I. A monte carlo evaluation of some ridge-type estimators. J. Amer. Statist. Assoc., 70:407–416, 1975.
[28] Golub G.H., Heath M., Wahba G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics, 21::215–223, 1979.
[29] Craven P., Wahba G. Smoothing noisy data with spline functions. Numer. Math., 31:377–403, 1978.
[30] Smith D.M., Hart F.A., Symond R.D., Walsh J.N. Analysis of Roman pottery from Colchester by inductively coupled plasma spectrometry. Sci. Archaeolog. Glasgow, 196:41-55, 1987.


